Getting the best performance of POV-Ray 3.6 for Unix
on x86 and x86-64 platforms (Part I)
Nicolas Calimet 1
Published online November 4th, 2004
Table of contents
|
1 e-mail contact:
nicolas dot calimet at povray dot org
|
|
|
This article, the first of a series of two, compares the performance
in running several binaries of POV-Ray 3.6.1 for Unix on a wide
variety of x86 platforms.
The machines tested feature 12 processors in 5 architectures
spanning from the good-old Intel Pentium III and AMD Duron to the recent
Intel Xeon and AMD Opteron.
The benchmarks are conducted on the GNU/Linux operating system
running in 32 or 64-bit mode depending on the architecture.
Several versions of the GCC and Intel C++
compilers are used to produce the POV-Ray binaries which are optimized
for the host platform.
The 32-bit official POV-Ray 3.6.1 for Linux
binary is also benchmarked for comparison.
These POV-Ray benchmarks demonstrate the performance boost that is
gained in compiling the POV-Ray 3.6 sources using more aggressive
optimizations than those utilized for the official binary.
With the newest processors (Intel Pentium 4, Xeon, Pentium-M;
AMD Opteron) it is possible to speedup the official
POV-Ray benchmark by as much as 33% using a self-compiled binary.
On older Intel platforms such as the Pentium III, one can expect
a 15% speedup in building the program with the current compilers.
To the contrary, the AMD K7 architecture (Athlon familly) hardly gets
a 5% speedup with respect to the official binary: using the latter may
thus suffice in most situations.
The benchmarks also confirm on most platforms that the latest GCC 3.4
and ICC 8.1 series tend to produce faster binaries than when using
earlier releases.
Additionally, there is still a significant performance gap in favor on the
very efficient ICC compiler on nearly all Intel platforms and the
AMD64 (in 32-bit mode only).
Overall, this study emphasizes the need to build POV-Ray 3.6 from
sources with a recent compiler to expect maximum performance as
measured by running the official POV-Ray benchmark.
|
| © 2004 Nicolas Calimet. All rights reserved. |
|
Keywords: POV-Ray benchmarks;
compiler performance; optimized binaries; ray-tracing.
|
|
Introduction
Purpose of this article
The goal of this article is twofold.
First, the article compares the relative performances of the
official POV-Ray 3.6.1 for Linux
binary and several unofficial compiles optimized specifically for
the various host platforms tested.
The official POV-Ray for Linux binary is prepared so as to equally
run on any Intel Pentium-compatible processor, i.e. for maximum
compatibility rather than best performance.
Such generic binary might consequently perform significantly slower
than self-made binaries which may benefit from additional
platform-specific optimizations.
The unofficial binaries are built from the official source distribution of
POV-Ray 3.6.1 for Unix using either the GNU Compiler Collection (GCC)
or the Intel
C++ Compiler (ICC), which are both freely available and widely
used on GNU/Linux.
Second, this study is also conducted to improve the support for
the ICC compiler (versus GCC) in the build system used to compile
POV-Ray 3.6 for Unix from sources.
The ICC compiler is known to be very efficient on the Intel platforms
and, to some extent, on the recent AMD processors.
In the Methods section of this article,
I will point out the weaknesses of the current build system with
respect to the use of the ICC compiler, and basic guidelines will
be given to work around them.
In time, additional (and commercial) compilers might be better
supported by the build system too.
Hopefully the next POV-Ray releases will help even further in getting
automatically the best performance of POV-Ray 3.6 for Unix on x86 platforms.
Platforms tested
The following twelve x86 platforms were used for benchmarking POV-Ray 3.6 for Unix:
| Brand | Arch. | Familly (core) | CPU Freq. | L2 cache | FSB |
|---|
| AMD | K7 | Duron (Spitfire) | 600 MHz | 64 KB | 100 MHz |
| AMD | K7 | Athlon (Thunderbird) | 600 MHz | 64 KB | 200 MHz DDR |
| AMD | K7 | Athlon (Thunderbird) | 1.2 GHz | 256 KB | 266 MHz DDR |
| AMD | K7 | Athlon MP 1400+ (Palomino) | 1.2 GHz | 256 KB | 266 MHz DDR |
| AMD | K7 | Athlon XP 2400+ (Thoroughbred) | 2.0 GHz | 256 KB | 266 MHz DDR |
| AMD | K8 (AMD64) | Opteron 246 (Hammer) | 2.0 GHz | 1 MB | 800 MHz |
| Intel | P3 | Pentium III (Katmaï) | 450 MHz | 512 KB | 100 MHz |
| Intel | PM | Pentium-M (Banias) | 1.5 GHz | 1 MB | 400 MHz QDR |
| Intel | P4 | Pentium 4 (Northwood) | 2.6 GHz | 512 KB | 800 MHz QDR |
| Intel | P4 | Pentium 4 HT (Northwood) | 3.2 GHz | 512 KB | 800 MHz QDR |
| Intel | P4 | Xeon (Prestonia) | 2.4 GHz | 512 KB | 533 MHz QDR |
| Intel | P4 | Xeon (Prestonia) | 3.06 GHz | 512 KB | 533 MHz QDR |
All machines are running the GNU/Linux operating system (actually various
distributions based on a 2.4 Linux kernel).
There are however several notes regarding the test systems:
-
Most of these machines are either desktop or production platforms commonly
used in scientific computing, and are accessed remotely as non-priviledged
user.
As such, I cannot provide accurate informations regarding mainboard, chipset,
memory brand & timings, harddrive, and the like.
Detailed hardware information would be hardly useful anyway, given the very
different nature of the platforms tested.
Moreover these machines are meant to be rock-stable, so their raw performance
is necessarily not optimum for benchmarking.
To the contrary they can be viewed as good representative of "average"
rather than heavily specialized configurations.
-
Several machines are equipped with dual processors (SMP): the Intel
Pentium III and the Xeon machines, the AMD Athlon MP and Opteron.
The Hyperthreading feature of the Intel Pentium 4 HT processor is activated.
However, only a single CPU is used in running the various POV-Ray binaries
benchmarked here.
As of version 3.6, POV-Ray for Unix is a single-threaded and
non-parallel application.
-
All benchmarks are done on essentially idle processors.
Yet there are many other processes running, in particular deamons.
On SMP machines, another CPU-demanding job is usually running
at the same time, which can affect e.g. memory bandwidth.
Accurate timings must therefore consider the CPU time consumed by
the benchmark runs, not the usual elapsed (wall-clock) time.
Compilers and POV-Ray binaries
As stated before, the benchmarks are performed using:
The GNU compilers are equally referred to as "GCC" or "gcc" from now on.
Similarly, the Intel C++ Compiler for IA32 and for EM64T are
termed "ICC" or "icc" and "ICCE" or "icce", respectively.
Only the most recent compiler versions are tested (as of late september 2004).
There are no benchmarks for the now outdated gcc 3.0, 3.1 and 3.2 series
or the icc 7 series.
However,
the old gcc 2.95 series is included as it is still the default compiler
found in some GNU/Linux distributions (for instance Debian).
Surprisingly POV-Ray 3.6 compiles fine with it, but the benchmark results
will show that this stone-aged compiler should be generally avoided.
The following nomenclature is used throughout this article:
[cpu-]comp-ver[-opt] means an unofficial POV-Ray 3.6.1 for Unix
binary built on the 'cpu' platform with the compiler 'comp' version 'ver'
using the optimization options 'opt' (among others).
Brackets indicate optional items.
For instance p4-icc-8.1-ip means a POV-Ray binary prepared
on an Intel Pentium 4 platform with ICC version 8.1 using
the -ip compiler flag.
The -ip or -ipo flags indicate the use of Intel's Inter
Procedural Optimizations (IPO) applied either within
each source file (-ip) or within and accross all source files (-ipo).
Further compilation and computational details are given in the Methods section.
The official term refers to the precompiled
official POV-Ray 3.6.1 for Linux binary.
Note that none of the binaries is produced by taking advantage
of profile-guided optimizations (PGO).
This issue will be addressed in the second part of this article.
Results
The official POV-Ray
benchmark version 1.02 is used all along this study for each pair
of CPU / compiler tested.
The sections below report the benchmark results obtained for the
Intel platforms followed by the AMD ones.
The fastest platforms are presented first.
The graphs show the CPU timings in seconds (the lower, the better)
on the x-axis.
The timings are then sorted on the y-axis from lowest to highest, thereby
ranking the tested compilers according to their efficiency in producing
the fastest (top) or slowest (bottom) POV-Ray binary.
Results for the official and
fastest binaries are
colored for clarity.
Three benchmark runs are performed on each platform and compiler combination,
except for the Intel Pentium III / Pentium-M
and the AMD Athlon 600 / Duron 600, for a total of 270 independant
runs corresponding to about 236 CPU hours.
The repeated runs for each POV-Ray binary are conducted to estimate the
CPU timing fluctuations that can occur using the benchmarking conditions
described above.
Since 3 runs per binary are not enough to derive timing statistics, only the
fastest is reported.
Timing fluctuations are usually not significant compared to the
overall compiler ranking (data not shown).
Intel platforms
Intel Pentium 4 HT @ 3.2 GHz

|
All but the gcc-2.95.3 binary (5% slowdown)
clearly outperform the official compile.
The fastest binaries are obtained using icc, with either the
-ip or -ipo inter procedural optimizations.
The icc-8.1 binaries are roughly 27-28% faster on running
the POV-Ray benchmark with respect to the official binary.
Following are the icc-8.0 binaries (22-23% speedup),
gcc-3.4.x (about 16%), and gcc-3.3.4 (13%).
The binaries prepared with the -ip optimizations are seemingly
slightly faster than those obtained with -ipo, but the overall
advantage is actually negligeable (less than 1%).
In contrast, the speed differences between the leading icc-8.1-ip
binary and the icc-8.0-ip or gcc-3.4.1 competitors are
significant, the first being about 5-6% and 14% faster than the second and
third, respectively.
|
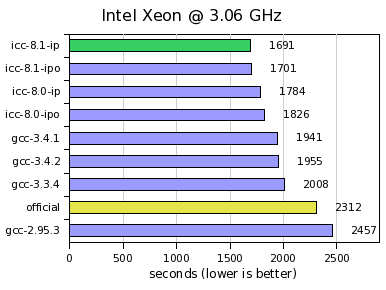
Intel Xeon @ 3.06 GHz
|
The Intel Xeon machine (used on a single CPU for each benchmark) reproduces
the exact scheme and ranking as the Intel Pentium 4 HT above.
The fastest binaries obtained with icc-8.1 outperform both
the official binary by 26-27% and the best binary
obtained with gcc (here gcc-3.4.1) by about 13%.
The gcc-3.4.x compilers produce binaries that are 15-16% faster
than the official one.
In between we find again the various binaries obtained with icc-8.0
and gcc-3.3.4 which speedup the benchmarks by 21-23% and 13%.
As before, the gcc-2.95.3 binary is out of competition
(6% slowdown).
|
Intel Pentium 4 @ 2.6 GHz

|
"Never change the winning team" could be the motto of the Intel
Pentium 4 player and its icc 8.x coach.
The binaries produced by the two icc versions are 27%
(icc-8.1) and 22-23% (icc-8.0) faster than the
official binary.
In comparison, the gcc-3.4.x and gcc-3.3.4 binaries
give a 16% and 11% speedup, respectively.
The icc 8.1 compiler is again leading its fastest gcc
competitor by about 13%.
Note here that the compiler ranking is not exactly preserved, e.g.
icc-8.0-ipo is slightly ahead of icc-8.0-ip; yet
those differences are hardly significant (<1%).
The differences between two compiler generations is a worthwile 5-6%
(icc-8.1 versus icc-8.0 and gcc-3.4.x
versus gcc-3.3.4).
|
Intel Xeon @ 2.4 GHz

|
The Xeon 2.4 GHz also gives all its power with a binary produced with
icc 8.1 or icc 8.0 as a second choice.
The various speedups againts the official binary are
26-27% (icc-8.1), 20-23% (icc-8.0), 16%
(gcc-3.4.x), 13% (gcc-3.3.4), and the expected
6% slowdown for the gcc-2.95.3 binary.
Overall the icc compiler confirms its leadership on all Intel
Pentium 4 and Xeon processors.
|
Intel Pentium M @ 1.5 GHz

|
With the Intel Pentium-M processor we go to a very different architecture
and to completely different timings and compiler ranking.
The official binary is now by far the slowest binary, and for
the first time the gcc-2.95.3 binary is faster by about 14%.
All the other binaries are 30-33% faster, which constitutes the
highest speedup observed so far.
The gap between the icc and gcc binaries is virtually cancelled,
particularly within the same compiler generations: there is about
1% difference between the gcc-3.4.x and icc-8.1
binaries, as well as between the gcc-3.3.4 and icc-8.0
ones.
Yet the speed differences between two compiler generations is roughly
preserved (e.g. 3-5% speedup from icc-8.0 to icc-8.1).
|
Intel Pentium III @ 450 MHz

|
The situation with the Intel Pentium III processor is very similar
to the Pentium-M, which is not surprising given their related micro
architecture (in particular much shorter pipelines than in the Intel
Pentium 4 and Xeon processors).
As compared to the newer Pentium-M however, the speedup relative to the
official binary is about half, reaching only 13-17% overall
and 7% for the gcc-2.95.3 binary.
Note that the Intel Pentium III processor cannot take advantage
of SSE2 optimizations, while the Intel Pentium-M does.
Interestingly, the icc-8.1 binaries are outperformed
by both the icc-8.0 and gcc-3.4.x compiles,
and rank around the gcc-3.3.4 binary.
|
Summary
On the recent Intel platforms (Pentium 4, Pentium-M, Xeon)
the POV-Ray unofficial binaries built with gcc 3.x and icc 8.x
are using SSE2 optimizations.
They offer a clear speed advantage over the official binary and the
unofficial binary prepared with gcc 2.95 which do not make use of
SSE/SSE2 at all.
On the older Intel Pentium III platform, re-compiling POV-Ray
seems to always give a small -yet worth- speedup, which may come from
better code generation for this platform (rather than the use of
SSE instructions).
AMD platforms
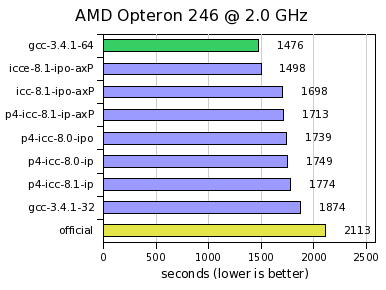
AMD Opteron 246 @ 2.0 GHz
|
The recent AMD64 architecture allows to run both 32 and 64-bit programs;
the binaries compiled with gcc are suffixed with -32 and
-64, respectively.
Note that gcc 3.3.4 fails to build POV-Ray on the AMD64
due to an internal compiler error (a bug in gcc).
Also the gcc 2.95.3 compiler itself cannot build there
(unsupported architecture).
For clarity, only a representative subset of all tested binaries are shown.
The gcc-3.4.1-64 binary is 21% faster than the equivalent 32-bit
binary (gcc-3.4.1-32) ran in 64-bit mode; such large speedup is
most likely due to the use of the 64-bit registers.
The same tendancy is observed for the 64-bit icce-8.1-ipo-axP
binary, though the speed advantage over the 32-bit icc-8.1-ipo-axP
is less than 12% here.
Interestingly, all 32-bit icc binaries, built on the Intel Pentium 4
plaftorm, outperform gcc-3.4.1-32 by 5-10%.
Overall, the speedup against the official 32-bit binary are
30% for the 64-bit gcc and icce compiles, 16-19% for the 32-bit icc compiles,
and 11% for the gcc-3.4.1-32 compile.
All of them use SSE2 optimizations, while the official binary
doesn't.
|
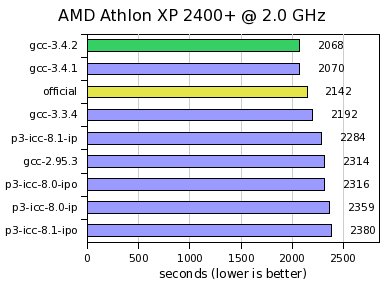
AMD Athlon XP 2400+ @ 2 GHz
|
The AMD Athlon XP architecture drastically changes the trend
observed so far: the official binary now ranks among the
first three fastest binaries.
All but the gcc-3.4.x binaries are 2% (gcc-3.3.4)
to 11% (p3-icc-8.1-ipo) slower.
The gain obtained from the binaries compiled with the lastest gcc series
(gcc-3.4.x) is also minimal, with slightly more than 3% speedup.
The performance discrepancies between the icc binaries may be the result
that none were prepared on the host platform.
Overall, the use of SSE optimizations seem to bring only little or even
no speedup (SSE2 instructions are not supported on the K7 platform).
|
AMD Athlon MP 1400+ @ 1.2 GHz

|
This machine gives pretty much the same picture as the AMD Athlon XP above,
which is not surprising given the architectures are nearly the same
(despite a core revision).
The speed difference between the various binaries is even flatten out:
there is now less than 1.5% speedup gained in compiling the source
with the gcc 3.4.x compilers with respect to the official binary.
Similarly, the difference between the fastest and slowest icc binaries
is less than 1.5%, and all are on average 7% slower than the official
binary.
This time the gcc-2.95.3 binary is ranked last, but it is virtually
as fast (or slow) as the icc compiles.
|
AMD Athlon @ 1.2 GHz

|
The same trends are observer on this older AMD Athlon platform, with
the leading gcc-3.4.x binaries outperforming the official
one by 4-5% at best.
There is however a slight reorganization in the ranking among the other
gcc and icc binaries, which is probably due to the fact that all those
binaries where compiled specifically on this platform (in contrast to
the AMD platforms presented above).
The icc binaries using -ip or -ipo optimization and the gcc-3.3.4
binary are all within +/- 2% off the official binary.
The gcc-2.95.3 binary is nearly 10% slower than the official
one.
Note that we introduce here an icc-8.0 binary (prepared
with optimizations similar to gcc-2.95.3 and official)
that is about 7% slower than icc-8.0-ipo.
|
AMD Athlon @ 600 MHz

|
Then again, on this older and slower processor we get the same sort of
performance ranking, with minor (unsignificant) rearrangements.
There is still less than 5% speedup with the fastest gcc-3.4.x
binaries.
All the other binaries but icc-8.1-ip are 2-10% slower.
|
AMD Duron @ 600 MHz

|
This slow AMD Duron machine somewhat changes the picture we've been facing
lately.
Here, only the non-IPO icc-8.0 and gcc-2.95.3 binaries
are relatively slower than the official one (2.5% and 4% respectively).
The gcc-3.4.1 binary also slightly outperforms the gcc-3.4.2
and the icc binaries that follows.
The speedups to the official binary are 8.5% (gcc-3.4.1),
6% (gcc-3.4.2), an average 5% (icc binaries using IPO
optimizations), and 3% (gcc-3.3.4).
|
Summary
On the recent AMD64 platform there is a strong advantage of recompiling
POV-Ray 3.6 from source, since this is the only way to make use of SSE2
optimizations and of the extra 64-bit registers which boost performance.
To the contrary, the official POV-Ray for Linux binary already performs
quite well on most of the AMD K7 platforms that do not support SSE2
instructions.
The official POV-Ray for Linux binary is thus well-suited for the K7
architecture (32-bit), but not for the K8 (particularly in 64-bit mode).
Discussion
Benchmarking with POV-Ray
POV-Ray is often used as a benchmarking application to evaluate and
compare the performance of various x86 processors under the Microsoft
Windows and GNU/Linux operating systems.
As such, it usually serves as a representative among several applications
known to stress different aspects of the system, and which are used for
deriving a global performance index.
For instance, on Microsoft Windows one can benchmark
a set of competing systems (or CPUs) using three categories of applications:
- the so-called "synthetic" benchmarks which specifically evaluate the
CPU and memory bandwidth (using e.g. CPUMark99, Super PI,
or SiSoftware Sandra);
- the 3D benchmarks, which mostly evaluate the performance of the GPU
coupled to the particular CPU/chipset/memory (using e.g. 3Dmark and recent DirectX/OpenGL games);
- benchmarks based on multimedia applications (e.g. audio/video-encoding),
file compression utilities, or office suites to evaluate the system as
a whole.
For benchmarking purposes, POV-Ray can be considered as belonging to
the first of these categories.
The present study does not aim at making yet another CPU comparison
using POV-Ray as a benchmarking tool, even though 12 different
processors are tested here.
This study is rather meant to help in getting the best performance
of the latest POV-Ray 3.6 series on the x86 platform in general, and
under the GNU/Linux operating system in particular.
It is likely that similar results can be obtained under Microsoft
Windows, at least with 32-bit binaries.
As a matter of fact, the official POV-Ray for
Windows 32-bit binary is also prepared for maximum compatibility
and is therefore not optimized for recent processors.
The results of this study are mostly targetted at users who want
to have POV-Ray run as fast as possible on their own machines.
However, they also are a strong hint for reviewers and testers
that they should not blindly use the official POV-Ray for Linux binary
in doing their x86 benchmarks.
(The same advice holds for the official POV-Ray for Windows binary.)
The figure below summarizes for the most recent platforms the speed
difference observed between the official binary and the fatest one
obtained by compiling POV-Ray with platform-specific optimizations:

As presented in the Results section, all of
these architectures but the now "old" AMD K7 (represented on the figure
by the AMD Athlon XP processor) show a drastic speedup,
up to 30%, in running the official POV-Ray benchmark.
The Intel Pentium-M (not shown here) even gains a worth 33%.
Note how the Intel Pentium 4 HT would apparently
remain slower than the AMD Athlon XP, while the optimized POV-Ray
binary actually performs more than 20% faster.
Similarly, it would be quite unfair to run the official 32-bit POV-Ray
binary on the AMD64 (Opteron), which gives a performance at the level
of the AMD Athlon XP clocked at the same 2.0 GHz.
Of course, in this particular case the unofficial compile also takes
advantage of the 64-bit extensions of the AMD64.
As POV-Ray 3.6 is fully 64-bit compatible, it does not make sense
to restrict POV-Ray to run in 32-bit mode on the AMD64 (and possibly the
newer Intel processors with the Intel
EM64T technology) unless it is benchmarked against another 32-bit
platform or operating system.
In summary,
this study clearly shows that using one single generic binary
(in this case the official POV-Ray for Linux binary) cannot reflect
the best possible performance of each CPU, especially on
the latest Intel and AMD architectures.
To the contrary, a generic binary may give results which are biased
toward a particular architecture: the lack of SSE2 optimizations in the
official POV-Ray for Linux binary artificially favors the AMD K7
over the Intel Pentium 4.
Therefore, when using POV-Ray as a benchmark application in particular
to compare equivalent CPUs from competing brands, it is wise to
re-compile the program from sources with the best possible optimizations.
For reliable results it is also recommanded to perform several benchmark runs
with each binary (as done in this study), and to report the fastest CPU
timings.
Compiler performances
In this study I compared the relative efficiency of a small set of compilers
in producing high-performance code for POV-Ray, a typical application that
heavily uses double precision floating-point arithmetics.
Only the GCC and Intel C++ compilers were evaluated, mostly for the reasons
that they are freely available on GNU/Linux and follow the ISO C++ standards
as much as possible.
Other free compilers (such as TenDRA, which ISO C++
support might not be complete enough at the moment) or
commercial ones (e.g. from The Portland Group, or PathScale
on the AMD64) were not investigated here.
One could argue that, for the sake of analyzing how to get the best
performance of POV-Ray 3.6 on the x86 platform, testing only two
compilers is somewhat limited; and this is true.
Except that more than two compilers are actually compared here, as
each evolution of the GCC and the Intel C++ compilers tend to show
we are dealing with different "products" altogether.
GCC 3.x has been a significative change
over its 2.x ancestor, particularly in its optimizer.
Here we also observe that there's already a performance
improvement between the two latest GCC 3.3 and 3.4 series.
It is expected that the next GCC 4.0 series will again improve its
code generation by using a relatively newer optimization framework.
(Note that, unlike another recent
benchmark study using POV-Ray, I choosed to only use stable compiler
releases in order to showcase benchmarks in accordance with the "production"
systems tested; so there are no results for the development GCC 4.0
series.)
Such a compiler improvement is even better observed here between the
8.0 and 8.1 releases of the Intel C++ compiler.
Thus, within the restriction of using freely available compilers,
comparing several versions of the GCC and the Intel C++ compilers already
give a relatively good coverage of compiler performance in this study.
Given that each compiler also provides several means in optimizing the
binaries they produce, as shown for instance in using Intel's variants
of the IPO optimizations (i.e. -ip versus -ipo),
testing additional compilers the same way would be hardly practical.
Moreover, the present study does not yet investigate profile-guided
optimizations, which will be the topic of the second part of this
article.
On the other hand, as stated in the Introduction
there is a will to better support alternate compilers in the POV-Ray
build system.
Another study comprising a larger compiler set may come in the future.
Regarding the support of the Intel
EM64T technology provided by the Intel
C++ compiler version 8.1,
there is a little point to raise concerning the AMD64 platform.
The Intel EM64T technology is now available in the latest high-end
Pentium 4 processors and corresponds to what AMD did
months ago with its 64-bit extensions in the AMD64 architecture.
As such, I was expecting ICC 8.1 for EM64T ("icce") to give a performance
boost on the AMD Opteron similar to that observed between the 32 and 64-bit
GCC compiles of POV-Ray.
A 12% performance boost is indeed observed on the AMD64, but it is nearly
half the speedup obtained when going from 32-bit to 64-bit with
GCC 3.4.x.
Given the already faster p4-icc-8.1-ipo 32-bit binary
versus gcc-3.4.1-32 on the AMD Opteron, it would have been logical
to see the ICC compiler leading the race in 64-bit mode too.
This is not the case at the moment, as GCC 3.4.x is slightly
ahead of its competitor.
Most likely the current situation only reflects the fact that, as first
released in september 2004, ICC 8.1 for EM64T is not mature enough
to efficiently optimize for the AMD64.
In this view, and to relativize a bit the whole point, the Intel compiler
is already performing quite good on the AMD64 processors and might
soon perform even better.
Conclusion
Running this series of POV-Ray benchmarks on very different
x86 platforms shows the overall benefit from re-compiling the sources
of POV-Ray 3.6 for Unix on the host machine, using a recent version of
the GCC or Intel C++ compilers.
While the oldest platforms (AMD Duron, Athlon, Athlon XP/MP and Intel
Pentium III) get a moderate 5-15% speedup,
the performance gain for newer processors (AMD Athlon64/Opteron, Intel
Pentium 4/Xeon and Pentium-M) is significant and can easily reach
up to 25-33%.
On the AMD K7 architecture it is best to use the latest GCC versions for
building POV-Ray from sources, or even to stick to the official POV-Ray
binary until a significantly faster GCC version (maybe 4.0 ?) is released.
On the other hand, the AMD64 architecture shows a drastic performance increase
when used in 64-bit mode.
Therefore, on the AMD Athlon64 and Opteron it is recommanded to build
POV-Ray 3.6 from sources using the GCC 3.4 series (in 64-bit mode)
or ICC 8.1 (in 32-bit mode).
Similarly, the platforms based on the Intel Pentium 4, Pentium-M
and Xeon architectures clearly benefit from the use of the SSE2 instructions
in the unofficial compiles.
Since the official POV-Ray binary cannot make use of the SSE2 instruction
set, it is strongly recommanded to re-compile POV-Ray 3.6 on the
Intel platforms, possibly using the latest version of the Intel C++ compiler.
Building the program from sources should be considered of high
importance for those using POV-Ray 3.6 as a CPU benchmark,
in particular when comparing recent processor architectures.
Since the so-called build system which manages the configuration and
compilation of the program has been completely revised in
POV-Ray 3.6, it is nowadays relatively easy to get a binary that
will maximize POV-Ray performance (as measured by running its official
benchmark) on a given x86 machine.
The POV-Ray build system will hopefully make this process even easier
in the near future.
Methods
Featured POV-Ray binaries
About 50 different binaries (but the official one) were
specifically prepared for this study by compiling the source distribution of
POV-Ray 3.6.1 for Unix.
The following table details the optimization flags passed to the compilers
for building the binaries which benchmark results are presented above.
The binaries are listed according to the nomenclature introduced previously.
Other binaries were prepared for testing purposes and are not listed
in the table but are shortly discussed in the next paragraph.
The colors enlight the official and
fastest binaries.
| POV-Ray binary | Optimization flags |
| All platforms |
| official (gcc-3.4.1) |
-O3 -march=i586 |
| AMD Athlon / Duron |
| athlon-gcc-2.95.3 |
-O3 -march=i686 -malign-double |
| athlon-gcc-3.3.4 |
-O3 -march=athlon -mcpu=athlon -malign-double -minline-all-stringops |
| athlon-gcc-3.4.1 |
-O3 -march=athlon -mtune=athlon -malign-double -minline-all-stringops |
| athlon-gcc-3.4.2 |
-O3 -march=athlon -mtune=athlon -malign-double -minline-all-stringops |
| athlon-icc-8.0 |
-O3 -march=i686 |
| athlon-icc-8.0-ip |
-O3 -march=pentiumii -mcpu=pentiumpro -ip |
| athlon-icc-8.0-ipo |
-O3 -march=pentiumii -mcpu=pentiumpro -ipo -ipo_obj |
| athlon-icc-8.1-ip |
-O3 -march=pentiumii -mcpu=pentiumpro -ip |
| athlon-icc-8.1-ipo |
-O3 -march=pentiumii -mcpu=pentiumpro -ipo -ipo_obj |
| AMD Athlon MP |
| athlonmp-gcc-2.95.3 |
-O3 -march=i686 -malign-double |
| athlonmp-gcc-3.3.4 |
-O3 -msse -mfpmath=sse -march=athlon-mp -mcpu=athlon-mp -malign-double -minline-all-stringops |
| athlonmp-gcc-3.4.1 |
-O3 -msse -mfpmath=sse -march=athlon-mp -mtune=athlon-mp -malign-double -minline-all-stringops |
| athlonmp-gcc-3.4.2 |
-O3 -msse -mfpmath=sse -march=athlon-mp -mtune=athlon-mp -malign-double -minline-all-stringops |
| athlonmp-icc-8.0-ip |
not built, p3-icc-8.0-ip used instead |
| athlonmp-icc-8.0-ipo |
not built, p3-icc-8.0-ipo used instead |
| athlonmp-icc-8.1-ip |
not built, p3-icc-8.1-ip used instead |
| athlonmp-icc-8.1-ipo |
not built, p3-icc-8.1-ipo used instead |
| AMD Athlon XP |
| athlonxp-gcc-2.95.3 |
-O3 -march=i686 -malign-double |
| athlonxp-gcc-3.3.4 |
-O3 -msse -mfpmath=sse -march=athlon-xp -mcpu=athlon-xp -malign-double -minline-all-stringops |
| athlonxp-gcc-3.4.1 |
-O3 -msse -mfpmath=sse -march=athlon-xp -mtune=athlon-xp -malign-double -minline-all-stringops |
| athlonxp-gcc-3.4.2 |
-O3 -msse -mfpmath=sse -march=athlon-xp -mtune=athlon-xp -malign-double -minline-all-stringops |
| athlonxp-icc-8.0-ip |
not built, p3-icc-8.0-ip used instead |
| athlonxp-icc-8.0-ipo |
not built, p3-icc-8.0-ipo used instead |
| athlonxp-icc-8.1-ip |
not built, p3-icc-8.1-ip used instead |
| athlonxp-icc-8.1-ipo |
not built, p3-icc-8.1-ipo used instead |
| AMD Opteron (and Athlon64) |
| k8-gcc-2.95.3 |
not built, the compiler itself cannot build (unsupported
architecture) |
| k8-gcc-3.3.4 |
not built, the compiler stops with an internal compiler error
(see a similar gcc bug reported
on the AMD64) |
| k8-gcc-3.4.1-32 |
-O3 -msse -mfpmath=sse -msse2 -march=k8 -mtune=k8 -minline-all-stringops -m32 |
| k8-gcc-3.4.1-64 |
-O3 -msse -mfpmath=sse -msse2 -march=k8 -mtune=k8 -minline-all-stringops |
| k8-icc-8.0-ip |
not built, p4-icc-8.0-ip used instead |
| k8-icc-8.0-ipo |
not built, p4-icc-8.0-ipo used instead |
| k8-icc-8.1-ip |
not built, p4-icc-8.1-ip used instead |
| k8-icc-8.1-ipo |
not built, p4-icc-8.1-ipo used instead |
| k8-icc-8.1-ipo-axP |
-O3 -march=pentium4 -mcpu=pentium4 -axP -ipo -ipo_obj |
| k8-icce-8.1-ip-axP |
-O3 -march=pentium4 -mcpu=pentium4 -axP -ip |
| k8-icce-8.1-ipo-axP |
-O3 -march=pentium4 -mcpu=pentium4 -axP -ipo -ipo_obj |
| Intel Pentium III |
| p3-gcc-2.95.3 |
-O3 -march=i686 -malign-double |
| p3-gcc-3.3.4 |
-O3 -march=pentium3 -mcpu=pentium3 -msse -mfpmath=sse -malign-double -minline-all-stringops |
| p3-gcc-3.4.1 |
-O3 -march=pentium3 -mtune=pentium3 -msse -mfpmath=sse -malign-double -minline-all-stringops |
| p3-gcc-3.4.2 |
-O3 -march=pentium3 -mtune=pentium3 -msse -mfpmath=sse -malign-double -minline-all-stringops |
| p3-icc-8.0-ip |
-O3 -march=pentiumiii -mcpu=pentiumpro -axK -ip |
| p3-icc-8.0-ipo |
-O3 -march=pentiumiii -mcpu=pentiumpro -axK -ipo -ipo_obj |
| p3-icc-8.1-ip |
-O3 -march=pentiumiii -mcpu=pentiumpro -axK -ip |
| p3-icc-8.1-ipo |
-O3 -march=pentiumiii -mcpu=pentiumpro -axK -ipo -ipo_obj |
| Intel Pentium 4 / Xeon |
| p4-gcc-2.95.3 |
-O3 -march=i686 -malign-double |
| p4-gcc-3.3.4 |
-O3 -msse -mfpmath=sse -msse2 -march=pentium4 -mcpu=pentium4 -malign-double -minline-all-stringops |
| p4-gcc-3.4.1 |
-O3 -msse -mfpmath=sse -msse2 -march=pentium4 -mtune=pentium4 -malign-double -minline-all-stringops |
| p4-gcc-3.4.2 |
-O3 -msse -mfpmath=sse -msse2 -march=pentium4 -mtune=pentium4 -malign-double -minline-all-stringops |
| p4-icc-8.0-ip |
-O3 -march=pentium4 -mcpu=pentium4 -axN -ip |
| p4-icc-8.0-ipo |
-O3 -march=pentium4 -mcpu=pentium4 -axN -ipo -ipo_obj |
| p4-icc-8.1-ip |
-O3 -march=pentium4 -mcpu=pentium4 -axN -ip |
| p4-icc-8.1-ip-axP |
-O3 -march=pentium4 -mcpu=pentium4 -axP -ip |
| p4-icc-8.1-ipo |
-O3 -march=pentium4 -mcpu=pentium4 -axN -ipo -ipo_obj |
| Intel Pentium-M |
| pm-gcc-2.95.3 |
-O3 -march=i686 -malign-double |
| pm-gcc-3.3.4 |
-O3 -msse -mfpmath=sse -msse2 -march=pentium4 -mcpu=pentium4 -malign-double -minline-all-stringops |
| pm-gcc-3.4.1 |
-O3 -msse -mfpmath=sse -msse2 -march=pentium-m -mtune=pentium-m -malign-double -minline-all-stringops |
| pm-gcc-3.4.2 |
-O3 -msse -mfpmath=sse -msse2 -march=pentium-m -mtune=pentium-m -malign-double -minline-all-stringops |
| pm-icc-8.0-ip |
-O3 -march=pentium4 -mcpu=pentium4 -axB -ip |
| pm-icc-8.0-ipo |
-O3 -march=pentium4 -mcpu=pentium4 -axB -ipo -ipo_obj |
| pm-icc-8.1-ip |
-O3 -march=pentium4 -mcpu=pentium4 -axB -ip |
| pm-icc-8.1-ipo |
-O3 -march=pentium4 -mcpu=pentium4 -axB -ipo -ipo_obj |
Note that in several cases the optimization flags are somewhat redundant:
for instance the ICC '-axN' flag superseedes (and is more precise than)
the corresponding '-march' flag.
For further details, please refer to the documentations of the respective
compilers.
Additionally a few binaries not presented above were tested:
- k8-gcc-3.4.2-64 which basically gives the same results
as the k8-gcc-3.4.1-64 binary on the AMD Opteron.
- p4-icc-8.0-ip-xN which uses the -xN compiler flag rather
than the -axN used in the other icc binaries prepared on the Intel
Pentium 4 architecture.
The -axN flag makes the icc compiler generate code for the Northwood core
as well as generic x86 code, while the -xN flag generates code that will
run only on the Northwood.
According to Intel's documentation,
the -xN flag might help producing slightly faster binaries.
I didn't record any performance gain whatsoever using -xN versus -axN with
POV-Ray 3.6.1.
Therefore I used -axN in all the other binaries, allowing to run them on
other platforms as well (e.g. AMD64).
The same line was taken for all the other binaries produced by icc/icce.
- k8-icce-8.1-ip-axW and k8-icce-8.1-ipo-axW
which code was generated for the Willamette core of the Intel
Pentium 4 processor (yet the binaries were produced on the AMD Opteron).
The binaries reported in the table make use of the -axP flag
which generates code for the newer Prescott core.
These are the two choices currently available with ICC 8.1 for EM64T,
i.e. -axN (Northwood) could not be used.
The binaries produced with -axW gave slightly slower benchmarks on the
AMD Opteron, so I discarded them in favor of the -axP variants.
Preparing the binaries
Most POV-Ray binaries were prepared on the various host platforms by compiling
a single POV-Ray 3.6.1 source tree over network (the machines share the
same filesystem).
This had the advantage to build several binaries in parallel while
minimizing disk usage.
Typically, the platform-specific files were created in a directory located
two levels down the root directory of the source tree, for instance in a
povray-3.6.1/build/p4-icc-8.1-ipo/ or a
povray-3.6.1/build/athlonmp-gcc-3.4.2 directory (see the nomenclature used for the POV-Ray binaries).
For practical reasons, the binaries for the AMD Athlon XP
and the Intel Pentium-M machines were built on an Intel Pentium 4
platform using the proper compiler options listed in the table above
(see the method below).
The POV-Ray binaries prepared with the GCC compiler (all versions
but GCC 2.95.3) were obtained directly from running POV-Ray's
configure script with default optimization settings.
The general command-line syntax was the following (to be typed on
a single line):
../../configure COMPILED_BY="my name" --enable-strip --disable-shared --disable-lib-checks --without-x --without-svga
The various configure options are described in the INSTALL file of
the POV-Ray for Unix source distribution.
Basically, the whole sources including that of the third-party libraries
were built as a static binary, similarly to the official POV-Ray for Linux binary
(thereby preventing any potential overload in using shared libraries
for the unofficial compiles).
All binaries were compiled without support for the X Window or SVGA display,
since some platforms are missing the related libraries; note that no display
is required for benchmarking.
All the other binaries (in particular those prepared with the Intel C++
compiler) were built by passing additional arguments to the
configure command-line.
Some of the additional arguments were required to work around
a few limitations of the configure script as found in
the source distribution of POV-Ray 3.6.1 for Unix:
- with old compilers such as the GCC 2.95 series
as well as with non-GNU compilers (that is ICC and ICCE here),
the configure script can fail to set a working compiler flag
used to generate code specifically for the host platform (i.e. the -march
flag).
This bug can cause configure to stop with error or to produce
invalid Makefiles that will prevent POV-Ray to build.
- with the Intel compilers (ICC and ICCE), in particular in its latest
8.1 version, configure does not yet do a good job at detecting
the best optimization flags for the platform: they must be passed at
the command-line instead.
In these cases, the following generic command-line was used (to be typed
on a single line):
../../configure COMPILED_BY="my name" --enable-strip --disable-optimiz --disable-shared --disable-lib-checks --without-x --without-svga CXX="C++ compiler" CC="C compiler" CXXFLAGS="C++ optimization flags" CFLAGS="C optimization flags"
The 'CXX' and 'CC' arguments allow to choose alternate compilers than the
default ones determined by configure (usually "g++" and "gcc"
respectively).
The 'CXXFLAGS' and 'CFLAGS' arguments, together with '--disable-optimiz',
are used to set manually the optimization flags for the host platform,
as listed in the table above.
Here is an example showing how the pm-icc-8.1-ipo binary
was produced, using a Bourne-compatible shell (bash).
Backslashes are used to split the command onto several lines for clarity:
flags="-O3 -march=pentium4 -mcpu=pentium4 -axB -ipo -ipo_obj"
../../configure COMPILED_BY="my name" --enable-strip \
--disable-optimiz --disable-shared --disable-lib-checks \
--without-x --without-svga \
CXX=icpc CC=icc CXXFLAGS="$flags" CFLAGS="$flags"
make
Further details regarding the usage of the configure script,
and of the build system of POV-Ray for Unix in general, are given in
the INSTALL file of the source distribution.
Running the official POV-Ray benchmark
For comparable and reproducible results, the official POV-Ray
benchmark version 1.02 was used.
In the POV-Ray for Unix 3.6 series, this benchmark is available in
two forms:
- a POV scene file (benchmark.pov)
and its accompanying INI file which defines the rendering settings (benchmark.ini);
- a builtin version
accessed via a new command-line option ('povray -benchmark').
While the builtin version is strictly identical to the version using files,
it requires POV-Ray to be properly installed on the system before
running it.
In this study, all the POV-Ray binaries were not installed after compilation
but ran directly from their respective build directory.
Such choice was made only to simplify maintenance (rather than usage)
of the many binaries tested.
For common usage however, it is strongly recommanded instead to install
the program as explained in the POV-Ray documentation; the exact procedure
depends on which of the available
distributions is being used.
After login on each machine, the following command-line was ran for
each binary tested (to be typed on a single line):
cd povray-3.6.1/scenes/advanced/ && nice time ../../build/cpu-comp-ver-opt/unix/povray benchmark.ini -L../../include
where cpu-comp-ver-opt follows the nomenclature described previously.
Note that the benchmark was ran by using the INI file, which tells POV-Ray
to read the scene in benchmark.pov and to render it according to the
provided settings.
Since the scene needs a few standard POV-Ray include files, the path
to the include directory was given on the command-line (this is not
necessary when the program is installed as usual).
The CPU time was monitored using the Unix 'time' command to get an
accurate measure: POV-Ray for Unix only reports wall-clock times at
completion, which in these benchmarks were usually significantly higher.
For practical reason, the Unix 'nice' command was used to deal with the
possible workload on the test systems (see the
platform notes); this command has no effect
on the CPU timings.
For each of the 3 benchmark runs computed per POV-Ray binary, the sum
of the "system" and "user" times (in seconds) was calculated as being the
true CPU timing.
The fastest run per binary was then reported against the other
POV-Ray binaries for each platform.
Acknowledgements
I would like to thank the members and friends of the POV-Team
and POV-TAG for support and comments on
the manuscript.
Christoph Hormann, in particular,
is acknowledged for having run the benchmarks on the Intel Pentium-M platform.
The indirect contributions to this work of Thierry Charles (SSE2 hints)
and Wolfgang Wieser
(patches to POV-Ray for Unix, among others)
are also appreciated, as well as useful feedback from the user community
on the POV-Ray newsgroups.
This study has been possible
thanks to the computer facilities of the Computational
Molecular Biophysics Lab at the Interdisciplinary Center
for Scientific Computing, University of Heidelberg,
Germany.